Jaemin Cho
Jaemin Cho
Selected Publications
All Publications
CV
Light
Dark
Automatic
Vision and Language
DOCCI: Descriptions of Connected and Contrasting Images
High-quality, long, human-annotated descriptions of 15K images
Yasumasa Onoe
,
Sunayana Rane
,
Zachary Berger
,
Yonatan Bitton
,
Jaemin Cho
,
Roopal Garg
,
Alexander Ku
,
Zarana Parekh
,
Jordi Pont-Tuset
,
Garrett Tanzer
,
Su Wang
,
Jason Baldridge
Preprint
Cite
Dataset
Project
SELMA: Learning and Merging Skill-Specific Text-to-Image Experts with Auto-Generated Data
SELMA improves T2I models by fine-tuning on automatically generated multi-skill image-text datasets, with skill-specific LoRA expert learning & merging.
Jialu Li
,
Jaemin Cho
,
Yi-Lin Sung
,
Jaehong Yoon
,
Mohit Bansal
Preprint
Cite
Code
Project
Contrastive Region Guidance: Improving Grounding in Vision-Language Models without Training
CRG is a training-free method that guides VLMs to help understand the visual prompts, by contrasting the outputs with & without visual prompts.
David Wan
,
Jaemin Cho
,
Elias Stengel-Eskin
,
Mohit Bansal
Preprint
Cite
Code
Project
Davidsonian Scene Graph: Improving Reliability in Fine-Grained Evaluation for Text-to-Image Generation
Reliable QG/A framework for T2I Evaluation based on Davidsonian Semantics -
ICLR 2024
Jaemin Cho
,
Yushi Hu
,
Roopal Garg
,
Peter Anderson
,
Ranjay Krishna
,
Jason Baldridge
,
Mohit Bansal
,
Jordi Pont-Tuset
,
Su Wang
Preprint
Cite
Code
Project
DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning
Using LLM (GPT-4) to generate a ‘diagram plan’ for fine-grained layouts (object/text labels/arrows, etc.) and render in either raster images (via diffusion) and vector graphics (via PowerPoint / Inkscape or any tools).
Abhay Zala
,
Han Lin
,
Jaemin Cho
,
Mohit Bansal
Preprint
Cite
Code
Project
VideoDirectorGPT: Consistent Multi-Scene Video Generation via LLM-Guided Planning
Using LLM (GPT-4) to generate a ‘video plan’ for consistent multi-scene video generation
Han Lin
,
Abhay Zala
,
Jaemin Cho
,
Mohit Bansal
Preprint
Cite
Code
Project
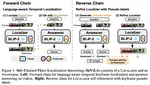
Self-Chained Image-Language Model for Video Localization and Question Answering
To handle video QA, we self-chain BLIP-2 for 2-stage inference (localize+QA) & refining localization via QA feedback -
NeurIPS 2023
Shoubin Yu
,
Jaemin Cho
,
Prateek Yadav
,
Mohit Bansal
Preprint
Cite
Code
Paxion: Patching Action Knowledge in Video-Language Foundation Models
Analyzing and patching action knowledge in video-language models -
NeurIPS 2023
(Spotlight)
Zhenhailong Wang
,
Ansel Blume
,
Sha Li
,
Genglin Liu
,
Jaemin Cho
,
Zineng Tang
,
Mohit Bansal
,
Heng Ji
Preprint
Cite
Code
Diagnostic Benchmark and Iterative Inpainting for Layout-Guided Image Generation
a New Diagnostic Benchmark (LayoutBench) and a new Baseline model (IterInpaint) for Layout-Guided Image Generation
Jaemin Cho
,
Linjie Li
,
Zhengyuan Yang
,
Zhe Gan
,
Lijuan Wang
,
Mohit Bansal
Preprint
Cite
Code
Dataset
Project
TVLT: Textless Vision-Language Transformer
Vision-and-Language modeling without text, by using a transformer which takes only raw visual and audio inputs -
NeurIPS 2022
(Oral)
Zineng Tang
,
Jaemin Cho
,
Yixin Nie
,
Mohit Bansal
Preprint
Cite
Code
»
Cite
×