1
HiREST is a holistic, hierarchical benchmark of multimodal retrieval and step-by-step summarization for a video corpus - CVPR 2023

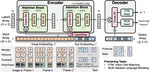
Vision-and-Language modeling without text, by using a transformer which takes only raw visual and audio inputs - NeurIPS 2022 (Oral)

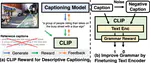
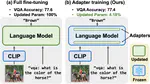
A question answering benchmark on real-world news articles for multi-media and multi-hop reasoning - AAAI 2022

