Ctrl-Adapter: An Efficient and Versatile Framework for Adapting Diverse Controls to Any Diffusion Model
Abstract
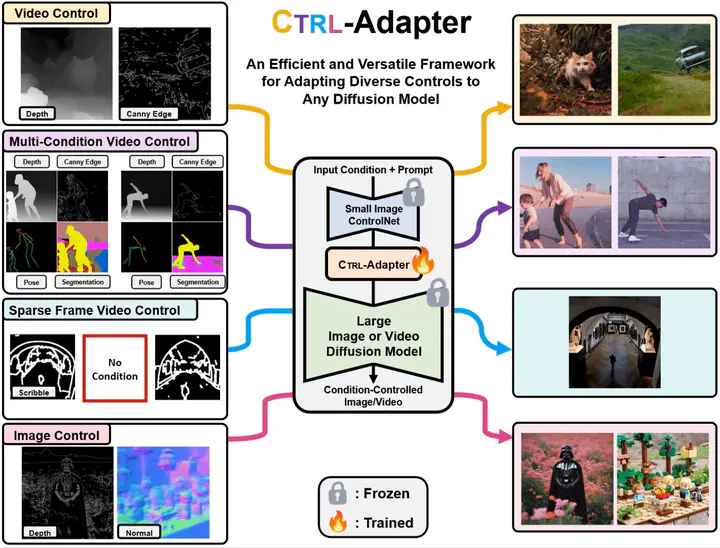
ControlNets are widely used for adding spatial control in image generation with different conditions, such as depth maps, canny edges, and human poses. However, there are several challenges when leveraging the pretrained image ControlNets for controlled video generation. First, pretrained ControlNet cannot be directly plugged into new backbone models due to the mismatch of feature spaces, and the cost of training ControlNets for new backbones is a big burden for many users. Second, ControlNet features for different frames might not effectively handle the temporal consistency of objects. To address these challenges, we introduce Ctrl-Adapter, an efficient and versatile framework that adds diverse controls to any image/video diffusion models, by adapting pretrained ControlNets (and improving temporal alignment for videos). Ctrl-Adapter provides strong and diverse capabilities including image control, video control, video control with sparse frames, multi-condition control, compatibility with different backbone models, adaptation to unseen control conditions, and video editing. In the Ctrl-Adapter framework, we train adapter layers that fuse pretrained ControlNet features to different image/video diffusion models, while keeping the parameters of the ControlNets and the diffusion models frozen. Ctrl-Adapter consists of temporal as well as spatial modules so that it can effectively handle the temporal consistency of videos. Additionally, for robust adaptation to different backbone models and sparse control, we propose latent skipping and inverse timestep sampling. Moreover, Ctrl-Adapter enables control from multiple conditions by simply taking the (weighted) average of ControlNet outputs. From our experiments with diverse image and video diffusion backbones (SDXL, Hotshot-XL, I2VGen-XL, and SVD), Ctrl-Adapter matches ControlNet on the COCO dataset for image control, and even outperforms all baselines for video control (achieving the state-of-the-art accuracy on the DAVIS 2017 dataset) with significantly lower computational costs (Ctrl-Adapter outperforms baselines in less than 10 GPU hours). Lastly, we provide comprehensive ablations for our design choices and qualitative examples.
Jaemin Cho
PhD student @ UNC Chapel Hill
PhD @ UNC Chapel Hill. Interested in multimodal machine learning.