DataEnvGym: Data Generation Agents in Teacher Environments with Student Feedback
Abstract
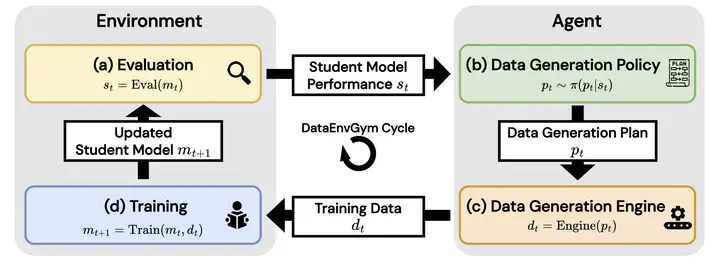
The process of creating training data to teach models is currently driven by humans, who manually analyze model weaknesses and plan how to create data that improves a student model. Recent approaches using LLMs as annotators reduce human effort, but still require humans to interpret feedback from evaluations and control the LLM to produce data the student needs. Automating this labor-intensive process by creating autonomous data generation agents - or teachers - is desirable, but requires environments that can simulate the feedback-driven, iterative, closed loop of data creation. To enable rapid and scalable testing for such agents and their modules, we introduce DataEnvGym, a testbed of teacher environments for data generation agents. DataEnvGym frames data generation as a sequential decision-making task, involving an agent consisting of a data generation policy (which generates a plan for creating training data) and a data generation engine (which transforms the plan into data), inside an environment that provides student feedback. The agent’s goal is to improve student performance. Students are iteratively trained and evaluated on generated data, with their feedback (in the form of errors or weak skills) being reported to the agent after each iteration. DataEnvGym includes multiple teacher environment instantiations across 3 levels of structure in the state representation and action space. More structured environments are based on inferred skills and offer more interpretability and curriculum control. We support 3 diverse tasks (math, code, and VQA) and test multiple students and teachers. Example agents in our teaching environments can iteratively improve students across tasks and settings. Moreover, we show that environments teach different skill levels and test variants of key modules, pointing to future work in improving data generation agents, engines, and feedback mechanisms.
Jaemin Cho
PhD candidate @ UNC Chapel Hill
PhD @ UNC Chapel Hill. Interested in multimodal machine learning.