DiagrammerGPT: Generating Open-Domain, Open-Platform Diagrams via LLM Planning
Abstract
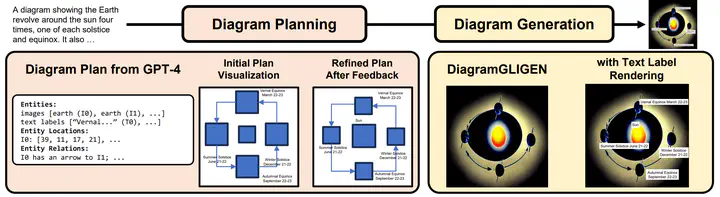
Text-to-image (T2I) generation has seen significant growth over the past few years. Despite this, there has been little work on generating diagrams with T2I models. A diagram is a symbolic/schematic representation that explains information using structurally rich and spatially complex visualizations (e.g., a dense combination of related objects, text labels, directional arrows, connection lines, etc.). Existing state-of-the-art T2I models often fail at diagram generation because they lack fine-grained object layout control when many objects are densely connected via complex relations such as arrows/lines and also often fail to render comprehensible text labels. To address this gap, we present DiagrammerGPT, a novel two-stage text-to-diagram generation framework that leverages the layout guidance capabilities of LLMs (e.g., GPT-4) to generate more accurate open-domain, open-platform diagrams. In the first stage, we use LLMs to generate and iteratively refine ‘diagram plans’ (in a planner-auditor feedback loop) which describe all the entities (objects and text labels), their relationships (arrows or lines), and their bounding box layouts. In the second stage, we use a diagram generator, DiagramGLIGEN, and a text label rendering module to generate diagrams following the diagram plans. To benchmark the text-to-diagram generation task, we introduce AI2D-Caption, a densely annotated diagram dataset built on top of the AI2D dataset. We show quantitatively and qualitatively that our DiagrammerGPT framework produces more accurate diagrams, outperforming existing T2I models. We also provide comprehensive analysis including open-domain diagram generation, vector graphic diagram generation in different platforms, human-in-the-loop diagram plan editing, and multimodal planner/auditor LLMs (e.g., GPT-4Vision). We hope our work can inspire further research on diagram generation via T2I models and LLMs.
Jaemin Cho
PhD student @ UNC Chapel Hill
PhD @ UNC Chapel Hill. Interested in multimodal machine learning.