Abstract
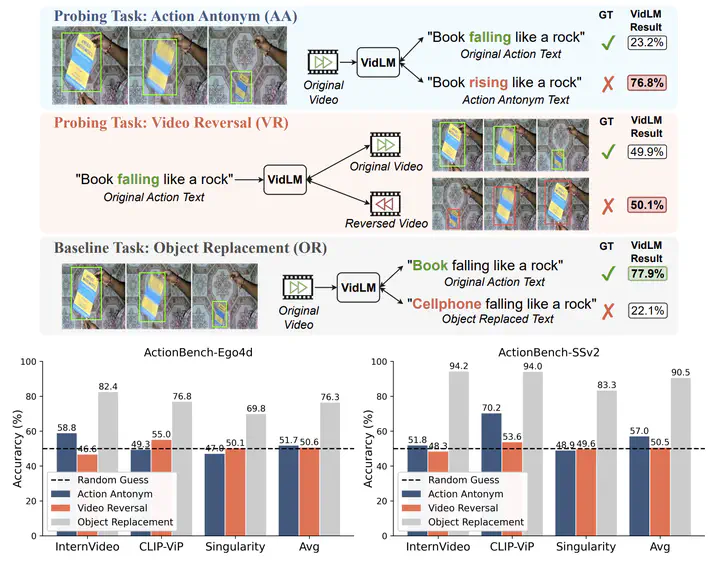
Action knowledge involves the understanding of textual, visual, and temporal aspects of actions. We introduce the Action Dynamics Benchmark (ActionBench) containing two carefully designed probing tasks - Action Antonym and Video Reversal, which targets multimodal alignment capabilities and temporal understanding skills of the model, respectively. Despite recent video-language models’ (VidLM) impressive performance on various benchmark tasks, our diagnostic tasks reveal their surprising deficiency (near-random performance) in action knowledge, suggesting that current models rely on object recognition abilities as a shortcut for action understanding. To remedy this, we propose a novel framework, Paxion, along with a new Discriminative Video Dynamics Modeling (DVDM) objective. The Paxion framework utilizes a Knowledge Patcher network to encode new action knowledge and a Knowledge Fuser component to integrate the Patcher into frozen VidLMs without compromising their existing capabilities. Due to limitations of the widely-used Video-Text Contrastive (VTC) loss for learning action knowledge, we introduce the DVDM objective to train the Knowledge Patcher. DVDM forces the model to encode the correlation between the action text and the correct ordering of video frames. Our extensive analyses show that Paxion and DVDM together effectively fill the gap in action knowledge understanding (~50% to 80%), while maintaining or improving performance on a wide spectrum of both object- and action-centric downstream tasks.
Jaemin Cho
Young Investigator @ AI2
Incoming Assistant Professor @ JHU
Incoming Asst. Prof. @ JHU working on Multimodal AI