VideoDirectorGPT: Consistent Multi-Scene Video Generation via LLM-Guided Planning
Abstract
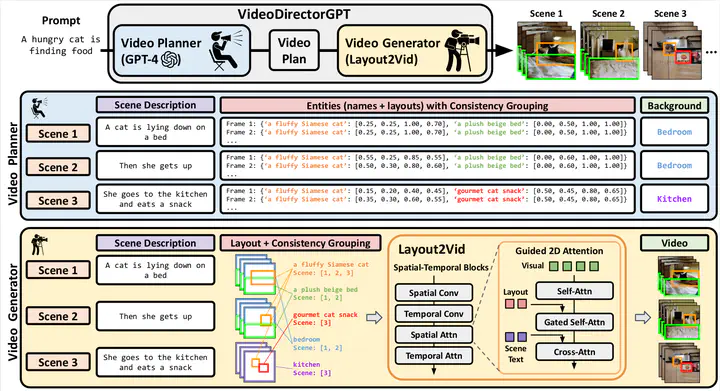
Although recent text-to-video (T2V) generation methods have seen significant advancements, most of these works focus on producing short video clips of a single event with a single background (i.e., single-scene videos). Meanwhile, recent large language models (LLMs) have demonstrated their capability in generating layouts and programs to control downstream visual modules such as image generation models. This raises an important question - can we leverage the knowledge embedded in these LLMs for temporally consistent long video generation? In this paper, we propose VideoDirectorGPT, a novel framework for consistent multi-scene video generation that uses the knowledge of LLMs for video content planning and grounded video generation. Specifically, given a single text prompt, we first ask our video planner LLM (GPT-4) to expand it into a ‘video plan’, which involves generating the scene descriptions, the entities with their respective layouts, the background for each scene, and consistency groupings of the entities and backgrounds. Next, guided by this output from the video planner, our video generator, Layout2Vid, has explicit control over spatial layouts and can maintain temporal consistency of entities/backgrounds across scenes, while only trained with image-level annotations. Our experiments demonstrate that VideoDirectorGPT framework substantially improves layout and movement control in both single- and multi-scene video generation and can generate multi-scene videos with visual consistency across scenes, while achieving competitive performance with SOTAs in open-domain single-scene T2V generation. We also demonstrate that our framework can dynamically control the strength for layout guidance and can also generate videos with user-provided images. We hope our framework can inspire future work on better integrating the planning ability of LLMs into consistent long video generation.
Jaemin Cho
PhD student @ UNC Chapel Hill
PhD @ UNC Chapel Hill. Interested in multimodal machine learning.