Abstract
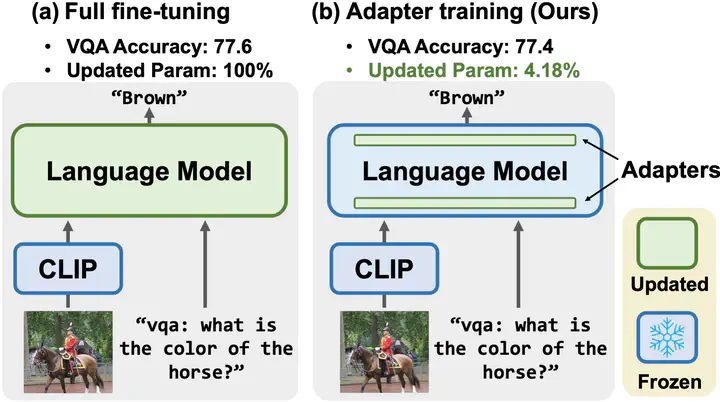
Recently, fine-tuning language models pre-trained on large text corpora have provided huge improvements on vision-and-language (V&L) tasks as well as on pure language tasks. However, fine-tuning the entire parameter set of pre-trained models becomes impractical since the model size is growing rapidly. Hence, in this paper, we introduce adapter-based parameter-efficient transfer learning techniques to V&L models such as VL-BART and VL-T5. We evaluate our methods in a unified multi-task setup on four diverse V&L tasks- VQAv2, GQA, NLVR2, and MSCOCO image captioning. With careful training and thorough experiments, we benchmark three popular adapter-based methods (Adapter, Hyperformer, Compacter) against the standard full fine-tuning and the recently proposed prompt-tuning approach. We also enhance the efficiency and performance of adapters by sharing their weights to attain knowledge across tasks. Our results demonstrate that training the adapter with the weight-sharing technique (4.4% of total parameters) can match the performance of fine-tuning the entire model. Lastly, we present a comprehensive analysis including the combination of adapter and task-specific prompts and the impact of V&L pre-training on adapters.
Jaemin Cho
Young Investigator @ AI2
Incoming Assistant Professor @ JHU
Incoming Asst. Prof. @ JHU working on Multimodal AI