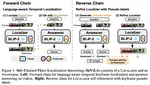
Vision and Language
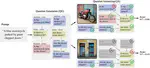
SELMA improves T2I models by fine-tuning on automatically generated multi-skill image-text datasets, with skill-specific LoRA expert learning & merging. - NeurIPS 2024
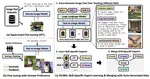
Using LLM (GPT-4) to generate a ‘diagram plan’ for fine-grained layouts (object/text labels/arrows, etc.) and render in either raster images (via diffusion) and vector graphics (via PowerPoint / Inkscape or any tools). - COLM 2024
Using LLM (GPT-4) to generate a ‘video plan’ for consistent multi-scene video generation - COLM 2024


CRG is a training-free method that guides VLMs to help understand the visual prompts, by contrasting the outputs with & without visual prompts. - ECCV 2024
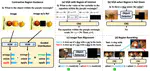
a New Diagnostic Benchmark (LayoutBench) and a new Baseline model (IterInpaint) for Layout-Guided Image Generation - CVPR Workshop 2024 (Oral)