Abstract
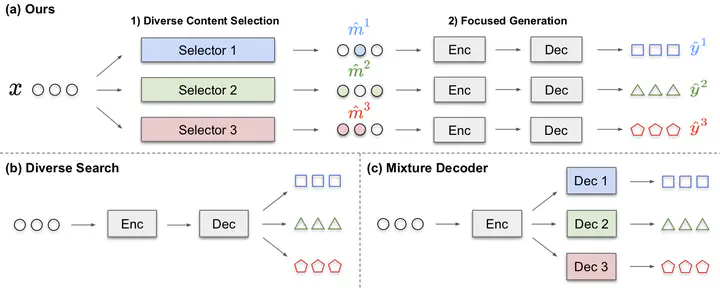
Generating diverse sequences is important in many NLP applications such as question generation or summarization that exhibit semantically one-to-many relationships between source and the target sequences. We present a method to explicitly separate diversification from generation using a general plug-and-play module (called SELECTOR) that wraps around and guides an existing encoder-decoder model. The diversification stage uses a mixture of experts to sample different binary masks on the source sequence for diverse content selection. The generation stage uses a standard encoder-decoder model given each selected content from the source sequence. Due to the non-differentiable nature of discrete sampling and the lack of ground truth labels for binary mask, we leverage a proxy for ground truth mask and adopt stochastic hard-EM for training. In question generation (SQuAD) and abstractive summarization (CNN-DM), our method demonstrates significant improvements in accuracy, diversity and training efficiency, including state-of-the-art top-1 accuracy in both datasets, 6% gain in top-5 accuracy, and 3.7 times faster training over a state of the art model. Our code is publicly available at https://github.com/clovaai/FocusSeq2Seq
Jaemin Cho
Young Investigator @ AI2
Incoming Assistant Professor @ JHU
Incoming Asst. Prof. @ JHU working on Multimodal AI