Video-Skill-CoT: Skill-based Chain-of-Thoughts for Domain-Adaptive Video Reasoning
Abstract
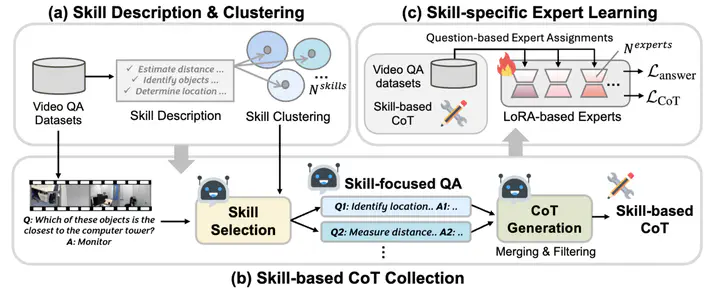
Recent advances in chain-of-thought (CoT) reasoning have improved complex video understanding, but existing methods often struggle to adapt to domain-specific skills (e.g., temporal grounding, event detection, spatial relations) over various video content. To address this, we propose Video-Skill-CoT a framework that automatically constructs and leverages skill-aware CoT supervisions for domain-adaptive video reasoning. First, we construct skill-based CoT annotations – We extract domain-relevant reasoning skills from training questions, cluster them into a shared skill taxonomy, and create detailed multi-step CoT rationale tailored to each video question pair for training. Second, we introduce a skill-specific expert learning framework. Each expert module specializes in a subset of reasoning skills and is trained with lightweight adapters using the collected CoT supervision. We demonstrate the effectiveness of the proposed approach on three video understanding benchmarks, where Video-Skill-CoT consistently outperforms strong baselines. We also provide in-depth analyses on comparing different CoT annotation pipelines and learned skills over multiple video domains.
Jaemin Cho
Young Investigator @ AI2
Incoming Assistant Professor @ JHU
Incoming Asst. Prof. @ JHU working on Multimodal AI