Abstract
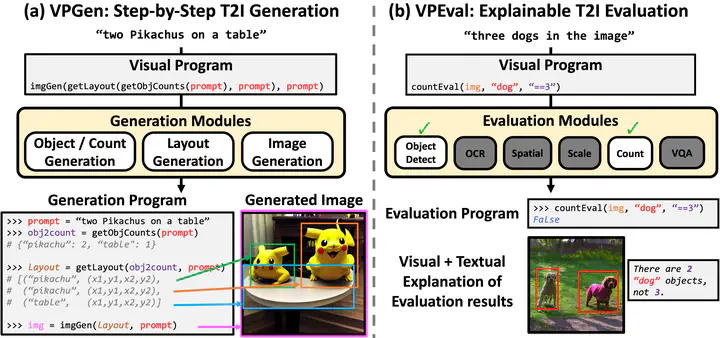
As large language models have demonstrated impressive performance in many domains, recent works have adopted language models (LMs) as controllers of visual modules for vision-and-language tasks. While existing work focuses on equipping LMs with visual understanding, we propose two novel interpretable/explainable visual programming frameworks for text-to-image (T2I) generation and evaluation. First, we introduce VPGen, an interpretable step-by-step T2I generation framework that decomposes T2I generation into three steps - object/count generation, layout generation, and image generation. We employ an LM to handle the first two steps (object/count generation and layout generation), by finetuning it on text-layout pairs. Our step-by-step T2I generation framework provides stronger spatial control than end-to-end models, the dominant approach for this task. Furthermore, we leverage the world knowledge of pretrained LMs, overcoming the limitation of previous layout-guided T2I works that can only handle predefined object classes. We demonstrate that our VPGen has improved control in counts/spatial relations/scales of objects than state-of-the-art T2I generation models. Second, we introduce VPEval, an interpretable and explainable evaluation framework for T2I generation based on visual programming. Unlike previous T2I evaluations with a single scoring model that is accurate in some skills but unreliable in others, VPEval produces evaluation programs that invoke a set of visual modules that are experts in different skills, and also provides visual+textual explanations of the evaluation results. Our analysis shows that VPEval provides a more human-correlated evaluation for skill-specific and open-ended prompts than widely used single model-based evaluation. We hope that our work encourages future progress on interpretable/explainable generation and evaluation for T2I models.
Jaemin Cho
Young Investigator @ AI2
Incoming Assistant Professor @ JHU
Incoming Asst. Prof. @ JHU working on Multimodal AI