X-LXMERT: Paint, Caption and Answer Questions with Multi-Modal Transformers
Abstract
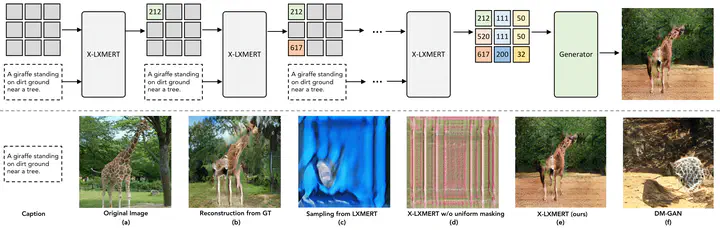
Mirroring the success of masked language models, vision-and-language counterparts like ViLBERT, LXMERT and UNITER have achieved state of the art performance on a variety of multimodal discriminative tasks like visual question answering and visual grounding. Recent work has also successfully adapted such models towards the generative task of image captioning. This begs the question - Can these models go the other way and generate images from pieces of text? Our analysis of a popular representative from this model family - LXMERT - finds that it is unable to generate rich and semantically meaningful imagery with its current training setup. We introduce X-LXMERT, an extension to LXMERT with training refinements including discretizing visual representations, using uniform masking with a large range of masking ratios and aligning the right pre-training datasets to the right objectives which enables it to paint. X-LXMERT’s image generation capabilities rival state of the art generative models while its question answering and captioning abilities remains comparable to LXMERT. Finally, we demonstrate the generality of these training refinements by adding image generation capabilities into UNITER to produce X-UNITER.
Jaemin Cho
Young Investigator @ AI2
Incoming Assistant Professor @ JHU
Incoming Asst. Prof. @ JHU working on Multimodal AI