Jaemin Cho
Jaemin Cho
Publications
Group
1
Imaginative Perception Tokens Enhance Spatial Reasoning in Multimodal Language Models
Imaginative Perception Tokens enhance spatial reasoning in multimodal language models -
ECCV 2026
Mahtab Bigverdi
,
Linjie Li
,
Weikai Huang
,
Yiming Liu
,
Jaemin Cho
,
Jieyu Zhang
,
Tuhin Kundu
,
Chris Dongjoo Kim
,
Zelun Luo
,
Ranjay Krishna
,
Linda Shapiro
Preprint
Cite
AnchorWeave: World-Consistent Video Generation with Retrieved Local Spatial Memories
Camera-controllable video generation with retrieved local geometric memories instead of a single global 3D reconstruction
Zun Wang
,
Han Lin
,
Jaehong Yoon
,
Jaemin Cho
,
Yue Zhang
,
Mohit Bansal
Preprint
Cite
V-Co: A Closer Look at Visual Representation Alignment via Co-Denoising
A systematic study of visual co-denoising for representation-aligned pixel-space diffusion
Han Lin
,
Xichen Pan
,
Zun Wang
,
Yue Zhang
,
Chu Wang
,
Jaemin Cho
,
Mohit Bansal
Preprint
Cite
Code
Physics Question Scene Graph: Fine-grained Evaluation of Physical Plausibility in Text-to-Video Generation
A hierarchical question-based pipeline (PQSG) for fine-grained evaluation of physical plausibility in text-to-video generation
Atin Pothiraj
,
Jaemin Cho
,
Yue Zhang
,
Elias Stengel-Eskin
,
Mohit Bansal
Cite
EPiC: Efficient Video Camera Control Learning with Precise Anchor-Video Guidance
Efficient and precise camera control learning for video diffusion models with anchor-video guidance —
ICML 2026
Zun Wang
,
Jaemin Cho
,
Jialu Li
,
Han Lin
,
Jaehong Yoon
,
Yue Zhang
,
Mohit Bansal
Preprint
Cite
Project
VideoRepair: Improving Text-to-Video Generation via Misalignment Detection and Localized Refinement
A new automatic refinement framework for T2V generation based on fine-grained text-video misalignment detection and localized refinement
Daeun Lee
,
Jaehong Yoon
,
Jaemin Cho
,
Mohit Bansal
Preprint
Cite
Code
Project
One Life to Learn: Inferring Symbolic World Models for Stochastic Environments from Unguided Exploration
OneLife learns symbolic programmatic world models from a single episode of unguided exploration in stochastic environments
Zaid Khan
,
Archiki Prasad
,
Elias Stengel-Eskin
,
Jaemin Cho
,
Mohit Bansal
Preprint
Cite
Project
RotBench: Evaluating Multimodal Large Language Models on Identifying Image Rotation
a benchmark evaluating MLLMs’ ability to identify image rotation
Tianyi Niu
,
Jaemin Cho
,
Elias Stengel-Eskin
,
Mohit Bansal
Preprint
Cite
Code
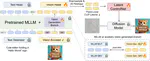
Bifrost-1: Bridging Multimodal LLMs and Diffusion Models with Patch-level CLIP Latents
a unified framework that bridges multimodal LLMs and diffusion models with patch-level CLIP latents
Han Lin
,
Jaemin Cho
,
Amir Zadeh
,
Chuan Li
,
Mohit Bansal
Preprint
Cite
Code
Project
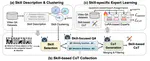
Video-Skill-CoT: Skill-based Chain-of-Thoughts for Domain-Adaptive Video Reasoning
a framework that automatically constructs and leverages skill-aware CoT supervisions for domain-adaptive video reasoning
Daeun Lee
*,
Jaehong Yoon
*,
Jaemin Cho
,
Mohit Bansal
Preprint
Cite
Code
Project
»
Cite
×