Abstract
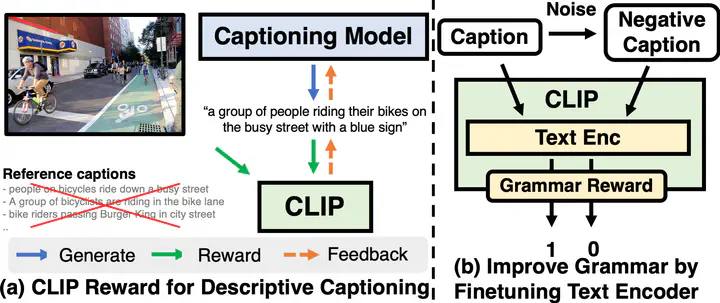
Modern image captioning models are usually trained with text similarity objectives. However, since reference captions in public datasets often describe the most salient common objects, models trained with text similarity objectives tend to ignore specific and detailed aspects of an image that distinguish it from others. Toward more descriptive and distinctive caption generation, we propose using CLIP, a multimodal encoder trained on huge image-text pairs from web, to calculate multimodal similarity and use it as a reward function. We also propose a simple finetuning strategy of the CLIP text encoder to improve grammar that does not require extra text annotation. This completely eliminates the need for reference captions during the reward computation. To comprehensively evaluate descriptive captions, we introduce FineCapEval, a new dataset for caption evaluation with fine-grained criteria - overall, background, object, relations. In our experiments on text-to-image retrieval and FineCapEval, the proposed CLIP-guided model generates more distinctive captions than the CIDEr-optimized model. We also show that our unsupervised grammar finetuning of the CLIP text encoder alleviates the degeneration problem of the naive CLIP reward. Lastly, we show human analysis where the annotators strongly prefer the CLIP reward to the CIDEr and MLE objectives according to various criteria.
Supplementary notes can be added here, including code, math, and images.
Jaemin Cho
Young Investigator @ AI2
Incoming Assistant Professor @ JHU
Incoming Asst. Prof. @ JHU working on Multimodal AI