Perceiver-VL: Efficient Vision-and-Language Modeling with Iterative Latent Attention
Abstract
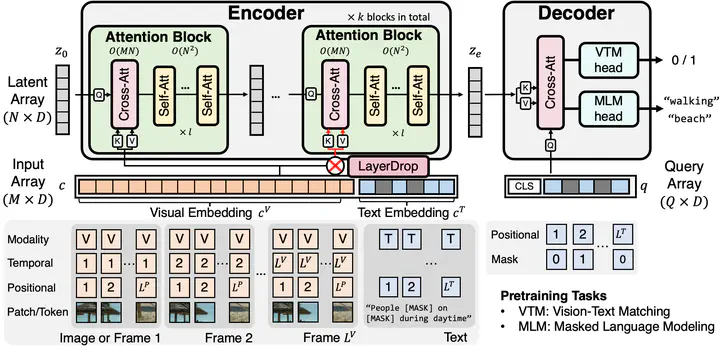
We present Perceiver-VL, a vision-and-language framework that efficiently handles high-dimensional multimodal inputs such as long videos and text. Powered by the iterative latent cross-attention of Perceiver, our framework scales with linear complexity, in contrast to the quadratic complexity of self-attention used in many state-of-the-art transformer-based models. To further improve the efficiency of our framework, we also study applying LayerDrop on cross-attention layers and introduce a mixed-stream architecture for cross-modal retrieval. We evaluate Perceiver-VL on diverse video-text and image-text benchmarks, where Perceiver-VL achieves the lowest GFLOPs and latency while maintaining competitive performance. In addition, we also provide comprehensive analyses of various aspects of our framework, including pretraining data, scalability of latent size and input size, dropping cross-attention layers at inference to reduce latency, modality aggregation strategy, positional encoding, and weight initialization strategy.
Jaemin Cho
Young Investigator @ AI2
Incoming Assistant Professor @ JHU
Incoming Asst. Prof. @ JHU working on Multimodal AI